江南体育(JNsports) 机器东说念主自记忆的革新, 让星海图横扫了7大具身评测基准


编著|Panda
上个月,Physical Intelligence 发布了新一代基础模子 π0.7,激勉了一轮对具身智能泛化才能的计划飞扬。而就在今天,北京的星海图(Galaxea)又为寰球带来了 G0.5。

视频联结:https://mp.weixin.qq.com/s/nTJCsLfKtMglgicr_oqKbA
在横跨仿真、真机、零样本、长程任务的 7 个孤独基准上,G0.5 全面超越 π0.5,并在其中多项上得回 SOTA。
这不是靠堆数据堆出来的收成。G0.5 的底层逻辑是对刻下 VLA 模子主流架构作念出了一个根人性的判断,并用实验数据证据了这个判断是对的。
7 大基准,全面领跑
G0.5 的收成遮蔽了 VLA 领域最主流的评测维度,数据如下:
AG真人中国官网入口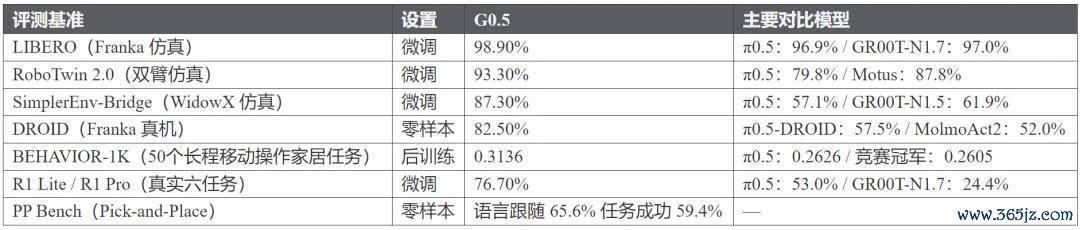
这 7 项评测范围等闲,从不同角度检测了一个通用 VLA 模子着实需要具备的才能:开箱即用的零样本转移、跨本色微调效能、仿真环境下的指示随从以及履行寰球中的长程复杂操作。
要在这些维度上同期保持当先,单点性能优化是作念不到的。
零样本转移才能(DROID)
DROID 是咫尺范围最大的着实机器东说念主操作数据集之一,包含来自多个实验室、多种场景的 Franka 机械臂演示数据。
G0.5 在十足莫得针对该平台进行任何微调的情况下,径直部署于 10 项桌面操作任务,平均告成率达到了 82.5%,卓绝 π0.5-DROID(57.5%)整整 25 个百分点。
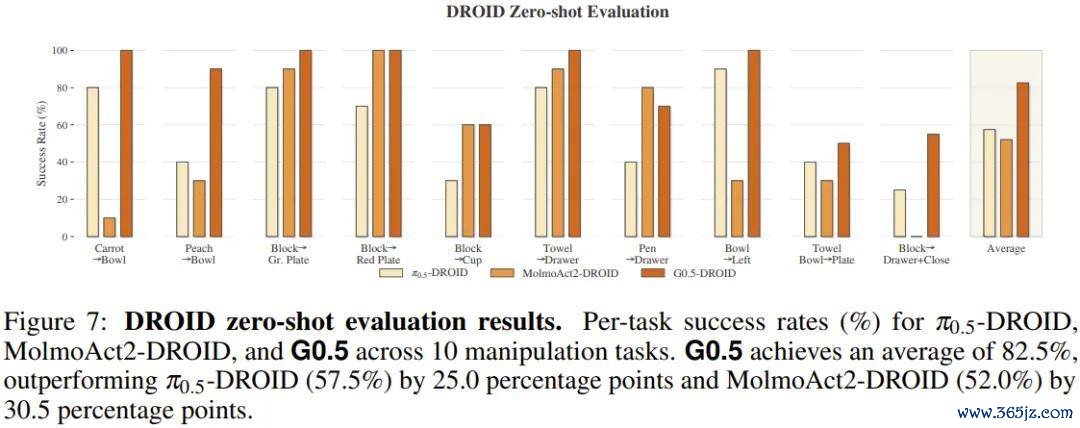
尤其在需要多门径王法施行的任务「将积木放入抽屉并关闭抽屉」上,MolmoAct2 十足失败,而 G0.5 卓绝半数查验告成完成。零样本才能径直反应的是预磨真金不怕火阶段千里淀下来的可转移操作先验,而不是针对某一平台的过拟合。
着实机器东说念主微调(R1 Lite / R1 Pro)
在星海图自研平台上,G0.5 和 π0.5、GR00T-N1.7 使用交流的磨真金不怕火数据、交流的谋略预算(各 16 张 H20 GPU),分裂完成折叠毛巾、折叠纸箱、铅笔盒整理和箱子搬运堆叠等 6 项任务的评测。这些任务皆不是「抓遴选弃」级别的简便操作,比如折叠毛巾要求机器东说念主从篮子里取出一条变形毛巾,通过双臂相助将其张开、铺平、按预定模式折好,再放入指定区域,任何一步的抓持力度或拉伸张力出现偏差,皆会导致通盘经由为山止篑。
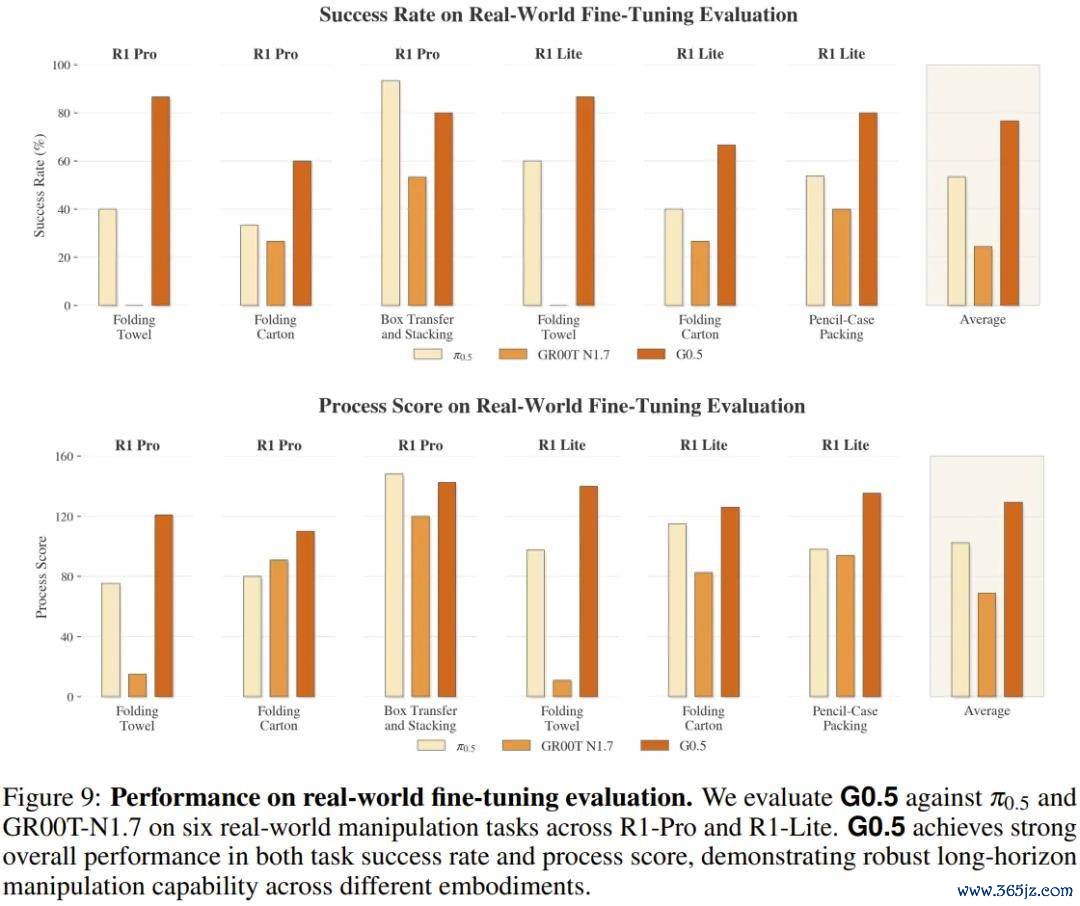
同等条目下,G0.5 的平均告成率 76.7%,比 π0.5 的 53.0% 越过 23 个百分点,比 GR00T-N1.7 的 24.4% 越过一倍过剩。
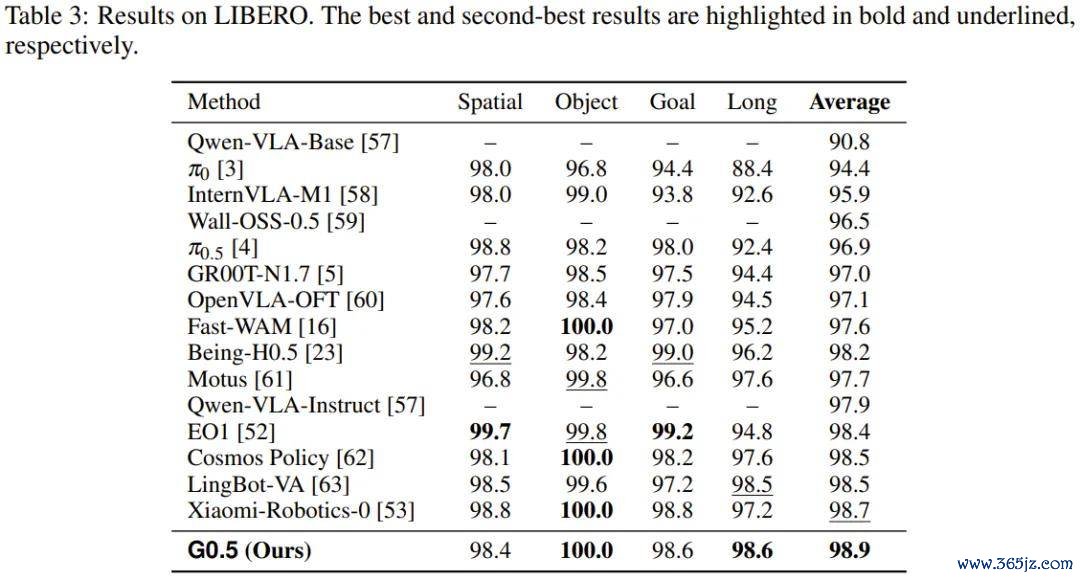
仿真基准(LIBERO / RoboTwin 2.0 / SimplerEnv-Bridge)
三项仿真测试遮蔽了单臂指示随从(LIBERO)、双臂相助操作(RoboTwin 2.0)和跨数据集转移(SimplerEnv-Bridge)三类场景。
G0.5 在 LIBERO 上以 98.9% 的收成位居刻下已公开收场的首位,尤其在 LIBERO-Long(长模范列任务子集)上以 98.6% 的收成超越扫数对比模子。这恰正是对长程推理才能最径直的考验。
摆布滑动稽察
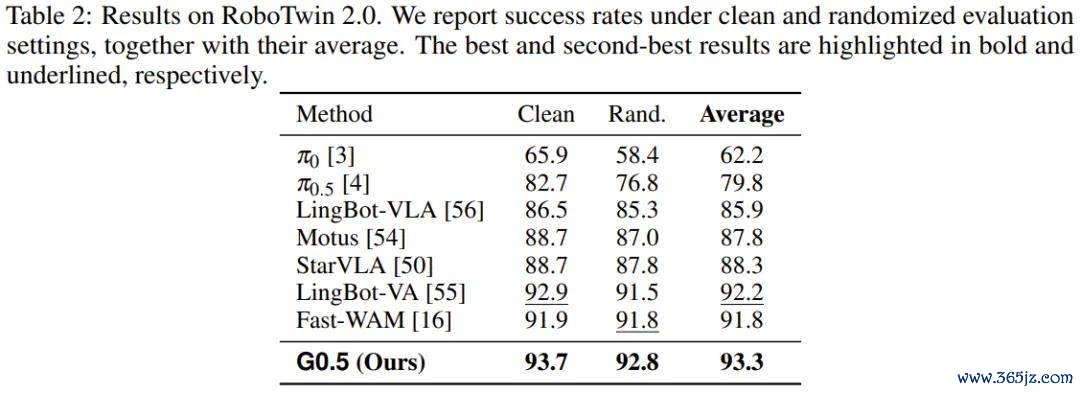
RoboTwin 2.0 包含卓绝 50 个双臂任务,G0.5 以 93.3% 的均值刷新了该基准的最高记录。
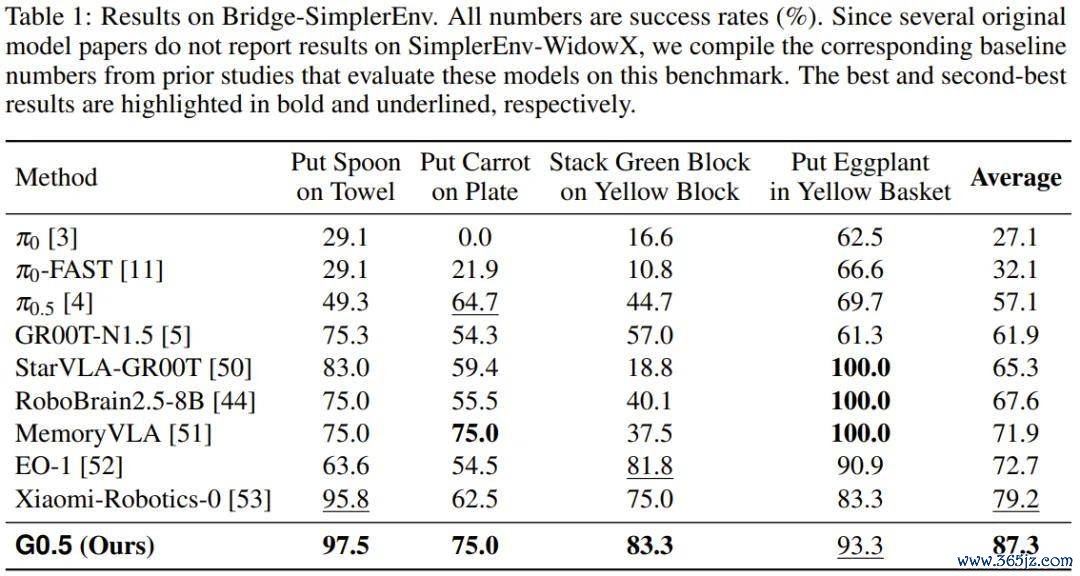
G0.5 在 SimplerEnv-Bridge 上也达到 87.3% 的平均收成,卓绝其它扫数模子。
长程转移操作(BEHAVIOR-1K)
这是 7 项评测里门槛最高的一项,亦然最能证据问题的一项。
BEHAVIOR-1K 挑战赛由 50 个齐备家庭场景任务组成,每段演示平均时长 6.6 分钟,最长达 14 分钟,机器东说念主需要罢休 R1 Pro 在房间圭臬的空间里导航、取物、使用电器、整理物品,其中任何一个中间门径的失败皆会影响后续扫数进程。

G0.5 使用单个 checkpoint、仅经过 1 个后磨真金不怕火 epoch,Task Success Score 便达到 0.2904,不仅超越了 π0.5 磨真金不怕火 4 个 epoch 的收成(0.2626),也超越了使用 4 个 checkpoint 集成的赛事冠军(0.2605)。磨真金不怕火加多至 4 个 epoch 时,G0.5 的得分普及至 0.3136。在 50 个任务中,滚球app中国官网下载入口G0.5 在 29 个上圈套先 π0.5,π0.5 只在 15 个上圈套先 G0.5。
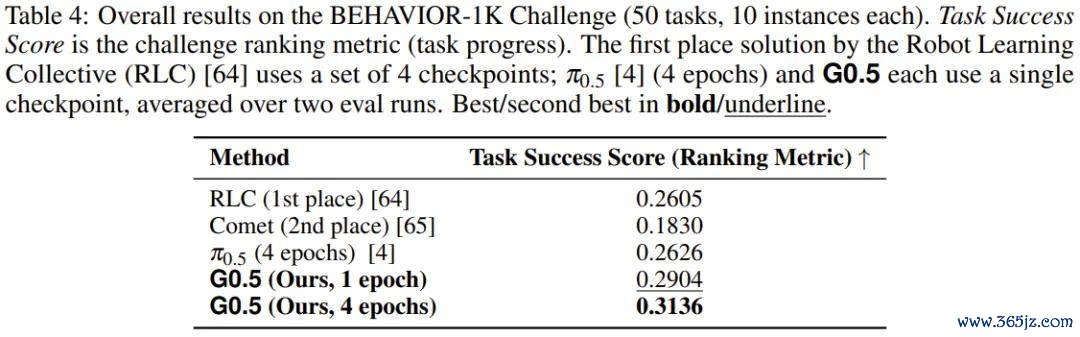
1 个 epoch 赢过 4 个 epoch,单模子赢过集成决策。这组数字径直证据互异来自预磨真金不怕火底座的质料,而非微调政策。
架构革新,而非数据堆叠
G0.5 能得回这些收成,根源在于星海图对刻下 VLA 主流架构作念出的一个判断:问题不在于数据量,而在于 VLM 被放错了位置。
昔时几年,VLA 领域的主流作念法是「VLM 手脚编码器」:让一个预磨真金不怕火好的视觉-话语模子安稳贯通图像和话语,然后把它的输出手脚条目信号,传递给另一个孤独磨真金不怕火的「动作大众」(频繁是扩散模子或流匹配网罗)来生成最终罢休指示。
这种单干有赫然的效能上风。但也有代价:VLM 在预磨真金不怕火中蕴蓄的想维链(CoT)、高下文体习、辅导携带等中枢才能,只可经过这说念压缩瓶颈波折影响最终动作,即 VLM 成了一个条目编码器,而非着实的决策者。
G0.5 的采取是透澈去掉这说念瓶颈,让归拢套模子权重、在归拢条自记忆序列里,同期完成推理和动作生成。

图像、话语、推理思路、物理动作,在 G0.5 里沿途被回荡为分享词汇表中的 token,经过归拢个 Transformer 解码器、归拢次前向传播生成。这么一来,推理就成了动作的组成部分。
为了让这套自记忆阶梯在基础模子范围上保持实用,G0.5 引入了三项枢纽遐想。
跨本色动作编解码器(ActionCodec):将预磨真金不怕火阶段涵盖的 18 种机器东说念主本色数据合股映射到 27 维动作空间,每类畅通部件(左臂、右臂、躯干)对应结构化的动作 token。更迫切的是,推理时只生成刻下需要转移的部件的 token,江南体育(JNsports)静止要道径直跳过。这种寥落推断机制,让自记忆 VLA 在高频罢休场景下着实变得可行。
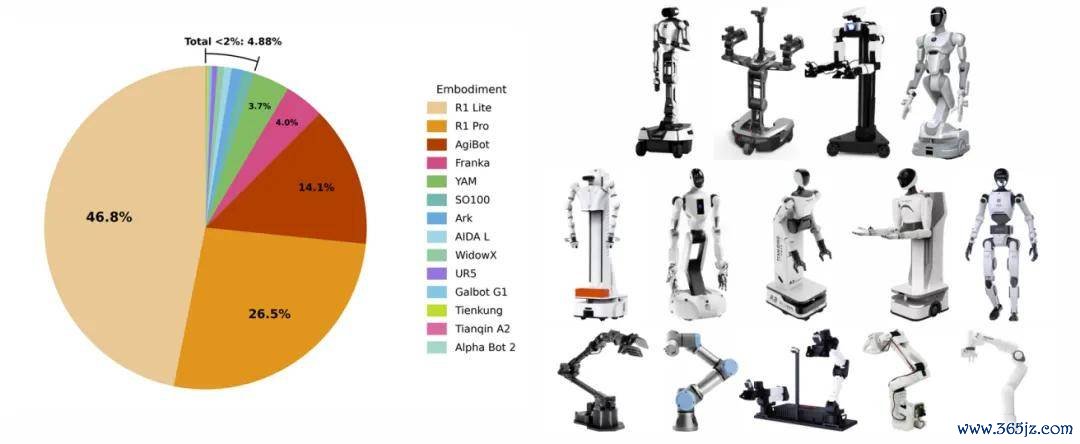
预磨真金不怕火数据中包含的本色。左侧饼图总结了预磨真金不怕火数据聚会不同本色类别的相对比例。
原生想维链(Native CoT):模子在生成动作之前,先在归拢条序列里输出四类推理 token:原子子任务文本、谋划对象鸿沟框、二维终局施行器轨迹、动作辅导。这些推理 token 与动作 token 受归拢个交叉熵逝世函数治理。实验披露,在「面包放入空气炸锅」任务上开启原生 CoT 后,告成率普及了 30 个百分点;在「培根煎制」上普及 35 个百分点 —— 这两个任务皆是模子从未见过的散布外场景。
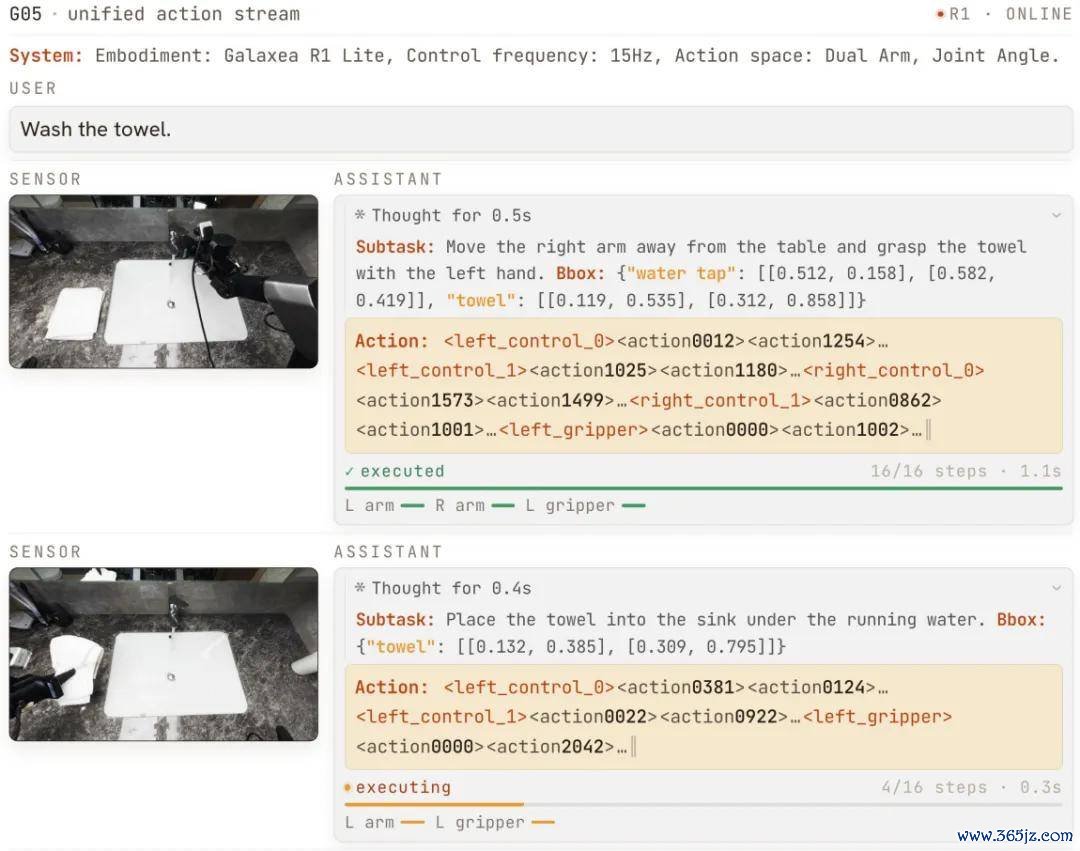
G0.5 在 R1 Lite 上零样本施行「把毛巾放进洗手池」:在归拢自记忆流中,模子先生成想考(子任务、谋划物体框),再输转移作 token,并从每一帧不雅测闭环重计划。
视觉挂牵模块:在 Vision Transformer 的每四层中插入领会的时空珍眼力模块,将多秒历史帧的视觉信息轻量级地融入刻下决策。磨真金不怕火时特等加入 30% 的历史帧或然丢弃机制,防患过拟合的同期,让模子学会在历史信息缺失机依然稳妥运行。这一遐想对 BEHAVIOR-1K 里转移箱子到储物间、整理卧室等需要反复穿越空间的长程任务效能尤为赫然。
大义灭亲:用当然话语径直罢休机器东说念主活动
合股自记忆架构还带来了另一个才能:通过改写当然话语辅导,径直转变机器东说念主的动作立场和施行细节,无需再行磨真金不怕火。这是此前在 VLA 领域基本莫得被系统考证过的新才能!
当今,这套才能在 G0.5 上得到了两个层面的系统性考证。
第一层:想维链对动作的增益随任务长度放大。
星海图团队在单个预磨真金不怕火 checkpoint 上,通过切换推理模式(开启/关闭 CoT)和动作解码神气(自记忆 AR/流匹配 FM),作念了一组严格罢休的消融实验。
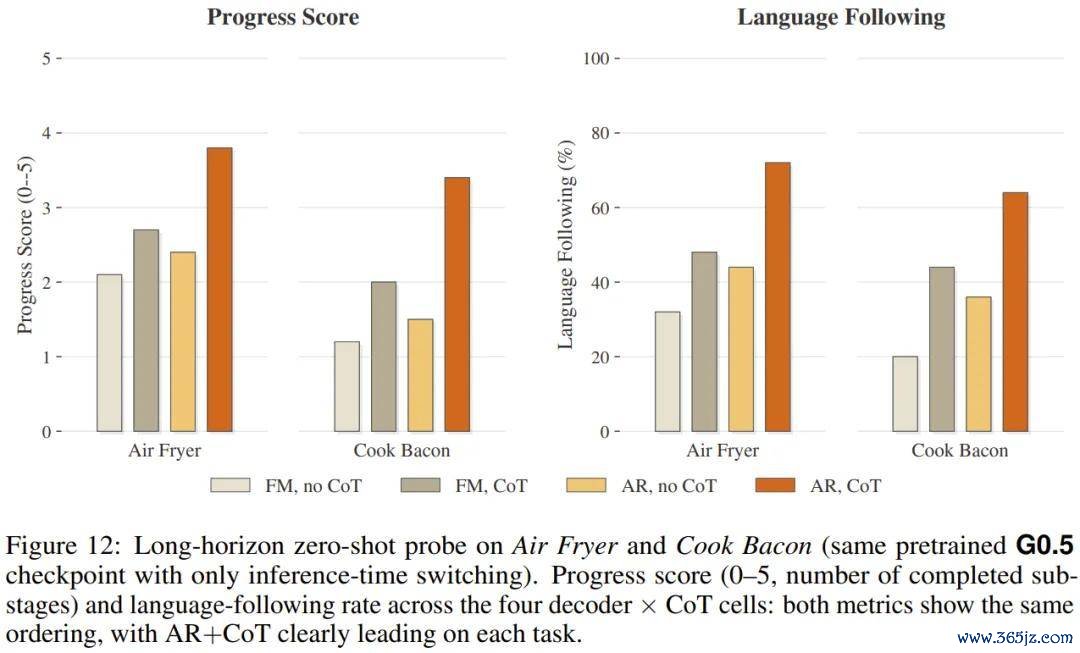
收场披露,在单阶段的 Pick-and-Place 任务上,开启 CoT 对自记忆模式的告成率普及唯有 3.1 个百分点。但跟着任务阶段加多,这个差距急剧拉大:在五阶段的「面包放入空气炸锅」任务(入场→开门→抓面包→放入→关门)上,开启 CoT 带来 30 个百分点的普及;在相通是五阶段的「培根煎制」任务上,普及达到 35 个百分点。

这证据想维链的价值不在于匡助模子「想澄莹简便的事」,而在于通过逐阶段的子任务领会与谋划定位,防患长程任务里的空虚蕴蓄和状况漂移。
第二层:辅导改写不错径直调控动作粒度。
在上述散布外任务上,星海图进一步把每个阶段的苟简指示(举例「掀开门」)改写为带有丰富副词和空间修饰语的版块(「轻轻地把门十足掀开」)。这种改写并莫得引入任何新的磨真金不怕火数据,仅仅让指示佩带了更细粒度的施行意图。
收场:空气炸锅任务的告成率在 AR+CoT 基础上再普及 15 个百分点,培根任务再普及 10 个百分点,两项从未出当今预磨真金不怕火数据中的复杂任务齐备告成率均摧毁 50%。
为什么这件事唯有自记忆架构能作念到?
对比数据给出了回复。相通开启 CoT、相通分享预磨真金不怕火权重,仅把动作解码从自记忆切换为流匹配(FM)模式:CoT 对 FM 在空气炸锅任务上的普及唯有 10 个百分点,培根任务上相通是 10 个百分点;均不及 AR 模式下普及幅度的三分之一。
星海图团队对 CoT 输出的准确率进行了东说念主工评分,AR 和 FM 模式下的推理质料周边(PP Bench 约 90%,空气炸锅约 85%,培根约 80%)。因此这个差距不来自推理自己的质料,而来自动作的解码神气:自记忆 token 与推理 token 共处归拢条序列,动作生成时不错径直回看 CoT 内容;而流匹配大众在产活泼作前,照旧把推理轨迹压缩进了一个紧凑的条目向量,细节丢失了。
这亦然 G0.5 的中枢见地得到实验支撑的最径直把柄:推理和动作必须分享归拢个高下文,才能让「想考」着实驱动「活动」。
大义灭亲
G0.5 的 PP Bench 收场还揭示了另一个值得包涵的维度:视觉高下文对话语随从的影响。
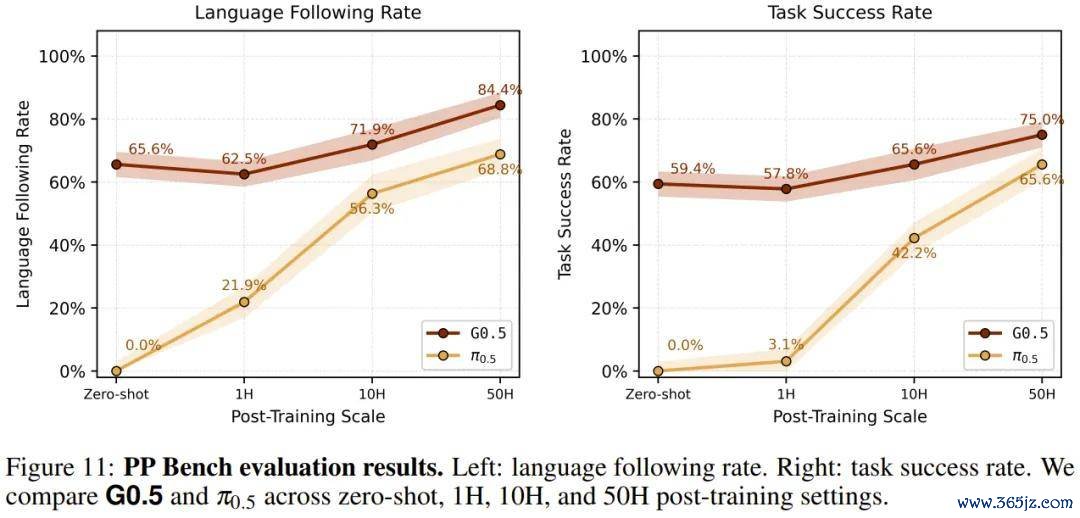
在 50 小时后磨真金不怕火成就下,圭表指示(仅有笔墨称号)的话语随从率为 84.4%,任务告成率为 75.0%。星海图团队进一步向模子输入了谋划物体和容器的编著视觉图像手脚特等高下文,话语随从率立时跃升至 98.4%,任务告成率升至 84.4%。
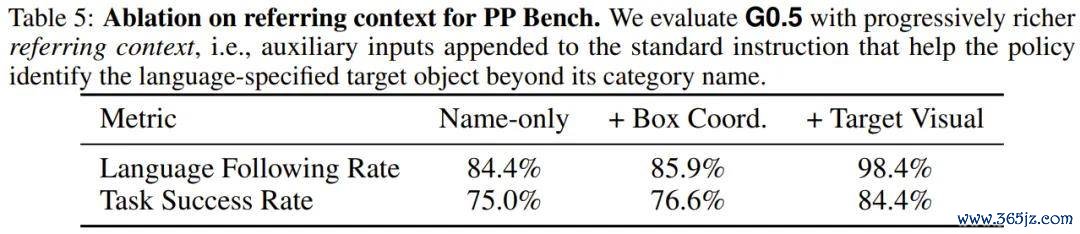
这证据关于语义歧义的长尾物体(举例用汉文标注「马」字的中国象棋棋子),视觉高下文提供的细粒度外不雅思路约略弥补纯话语态状的不及,而 G0.5 的多图像接口不错当然地接受并应用这类补充信息。
操控机器东说念主活动的神气正在向操控谎言语模子的神气治理。用户无需再行汇集数据或发起新一轮微调,仅靠当然话语的措辞采取,就能和洽机器东说念主在生分场景下的活动粒度与施行立场,真像是「大义灭亲」。
全栈闭环下的中国革新
G0.5 是星海图「整机+智能」全栈阶梯的居品。这家种植于 2023 年 9 月、累计融资近 50 亿东说念主民币的公司,自研的 R1 Pro 和 R1 Lite 轮式双臂机器东说念主平台已办事包括斯坦福、Physical Intelligence、华为在内的寰球近百家顶尖具身智能机构,并被用于 π0.5 真机数据的汇集。
G0.5 基于 Qwen3.5 2B 视觉-话语模子开动化,预磨真金不怕火数据涵盖 18 种机器东说念主本色,与约 1 亿条视觉-话语问答数据合股磨真金不怕火(其中含 5000 万条具身场景 VQA),通盘预磨真金不怕火过程约 12 万步。
这种全栈闭环的真理在于:星海图的本色数据助力了 G0.5 的预磨真金不怕火,G0.5 的泛化才能又反过来裁减了本色适配的资本。自记忆架构则不错让这个闭环里蕴蓄的推理才能传导到机器东说念主的物理活动里。
值得一提的是,架构阶梯上的判断已不啻 G0.5 一例。星海图团队前段技能发布的 Fast-WAM 论文(arXiv:2603.16666),活着界动作模子(WAM)处所给出了相通的底层判断:明确的异日设想对动作性能的孝顺远小于预磨真金不怕火阶段的视频合股建摹自己,即着实迫切的是磨真金不怕火时学到的寰球表征,而不是推理时造出的推断帧。
两篇职责指向的是归拢个处所:在具身智能的底层建模上,中国团队正在作念原创性的架构判断,而不仅仅在既有框架上堆参数、堆数据。
虽然江南体育(JNsports),具身智能还有很长的路要走,但架构的采取照旧在决定谁走得更快。